如何更改Django默认主页为自定义主页,更改Djago默认主页为自定义主页,这是开始网页的第一步。......
如何用python抓取网页数据
来源:互联网
2023-03-16 19:08:48 125
可能很多小伙伴们不是很清楚如何用python抓取网页数据,那么具体应该怎么做呢?感兴趣的小伙伴们随小编一起看看吧!

方法/步骤
在抓取网站中有两个基本的任务:
加载网页到一个 string 里。
从网页中解析 HTML 来定位感兴趣的位置。

Python 为上面两个任务提供了两个超棒的工具。我将使用requests去加载网页,用BeautifulSoup去做解析。

我们可以把上面两个包放到一个虚拟环境:
$ mkdir pycon-scraper$ virtualenv venv$ source venv/bin/activate(venv) $ pip install requests beautifulsoup4
如果使用的是 Windows 操作系统,注意上面虚拟环境的激活命令是不同的,你应该使用venv\Scripts\activate。

基本的抓取技术
在写一个爬虫脚本时,第一件事情就是手动观察要抓取的页面来确定数据如何定位。
首先,我们要看一看在http://pyvideo.org/category/50/pycon-us-2014上的 PyCon 大会视频列表。检查这个页面的 HTML 源代码我们发现视频列表的结果差不多是长这样的:

div id="video-summary-content"> div class="video-summary"> !-- first video --> div class="thumbnail-data">.../div> div class="video-summary-data"> div> strong>a href="#link to video page#">#title#/a>/strong> /div> /div> /div> div class="video-summary"> !-- second video --> ... /div> .../div>

那么第一个任务就是加载这个页面,然后抽取每个单独页面的链接,因为到 YouTube 视频的链接都在这些单独页面上。

以上方法由办公区教程网编辑摘抄自百度经验可供大家参考!
上一篇:在Python下安装scrapy 下一篇:在win7下安装Python最简单的方法
相关文章
- 详细阅读
-
python中关于单/双引号和转义引号的区别详细阅读
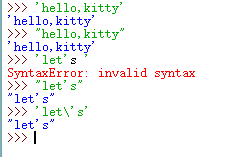
python中关于单/双引号和转义引号的区别,ytho中单/双引号的作用是将引号中间的符号以字符串的形式传递,而在ytho中它们两个的功能是一样的,只不过在遇到转义引号的时候,两者的使用才有所区别,现......
2023-03-16 317 python
- 详细阅读